LangLearn
March 2023
Try it for free at https://www.langlearn.app!
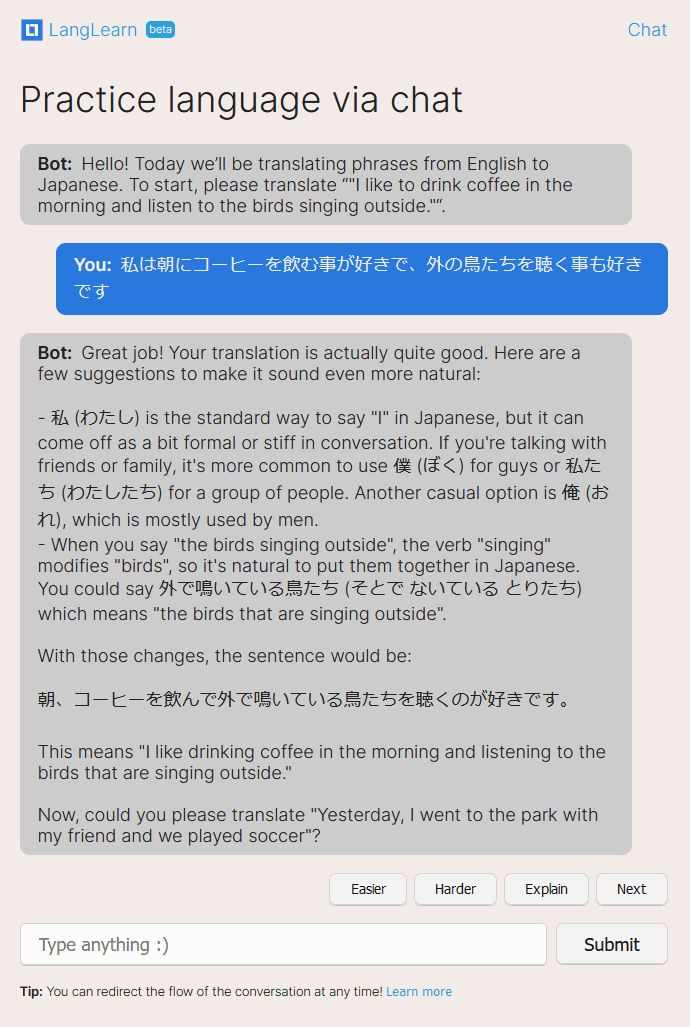
An example conversation of me using LangLearn to practice Japanese.
I started working on LangLearn in early March, 2023. About 10 days later, I was able to get a version that was polished enough to launch publicly. It would’ve been a bit faster (see the technical section below) had I not been messing around with serverless functions 😅. Currently, I’m marketing the app and seeing if there’s a product market fit.
Why build this?
The idea to build LangLearn came to me after a particularly satisfying ChatGPT interaction that I had while awake one sleepless night. A lot of my best ideas seem to happen at 2AM. I was chatting with ChatGPT, and for some reason, I decided to start trying to get it to quiz me on translating sentences to and from Japanese.
At some point, ChatGPT lapsed into 100% Japanese, and I had my first full Japanese immersion conversation experience. However, I was also able to get it to correct me on things that sounded incorrect or less than fluent, and explain why. When I received the first bulleted list of suggestions to improve my sentence, I knew that I was onto something powerful and incredibly useful. The immersion experience was icing on the cake, because to learn how to improve my sentence, I also had to be able to read and decipher the suggestion itself.
I’d been looking around for better ways to practice Japanese for a while. I looked through a directory of publicly available Discord servers with a Japanese focus, and I’d also heard of apps like italki, which match you up with a real human teacher. For both of these, I feel like there’s a few downsides:
- You have to find the community, evaluate it, build up relationships. These are not bad things, but they take time.
- There’s no guarantee that those in the community are truly fluent, so there’s a real potential to develop bad habits.
- Some of these approaches are paid, and likely cost more than the GPT API. Or, if unpaid, are not reliable.
- Lack of immediate 24/7 feedback and interaction. If the desire to practice Japanese strikes me at 2AM, I don’t want to wait for my tutor to come online.
Most of all, what I found was that when I was talking to ChatGPT, I wasn’t afraid of being incorrect. I was able to attempt to produce a sentence faster, get feedback instantly, all while feeling absolutely no pressure at all. You can’t disappoint a large language model (yet...?). It was OK to fail, and I was always better for it!
So, I think the AI-based approach can be a supplement for the traditional methods but with less (or a different set of) downsides.
The next day, I awoke, full of excitement, and couldn’t wait to start building it!
Features and examples
You can use any language (for the source and target languages), not just a language from a dropdown. This means you can even learn “Pirate”, “Klingon”, “Pig Latin”, or even “Very Rude English”.

At one point I considered having the language selection be dropdowns. I used a regular
<input>early in development to save on time, and so this feature was actually a happy accident.I predict that in the future we’ll see more cases where things that were once typically dropdowns are now replaced by free-form text entry, now that AI can disambiguate the nature of that free-form text. At the very least, AI-assisted searchable dropdowns.
The ability to have the bot talk to you in your native language (or source language), or in the target language. With this, you can achieve a full immersion experience.
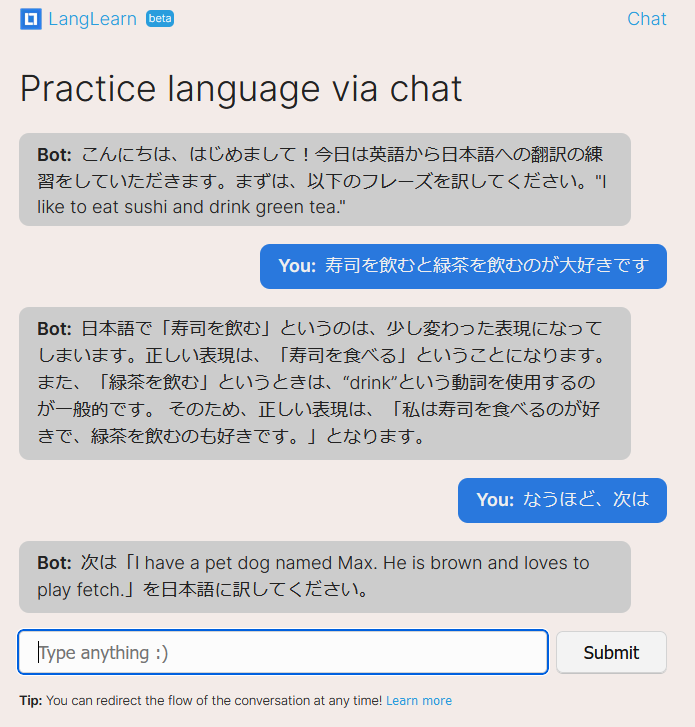
A screenshot of me talking to LangLearn in a Japanese immersion setting. もしかして、あなた様は日本語を話せば、私の「なうほど」タイポを許して下さいませんかw
This was tricky to implement because there’s potentially 3 languages at play: English (the language the prompts are written in), the user’s source language, and the destination language.
You can use it to workshop phrases if you’re feeling less confident but want to communicate with a human partner. For example, I used it to workshop the phrase above in this article!
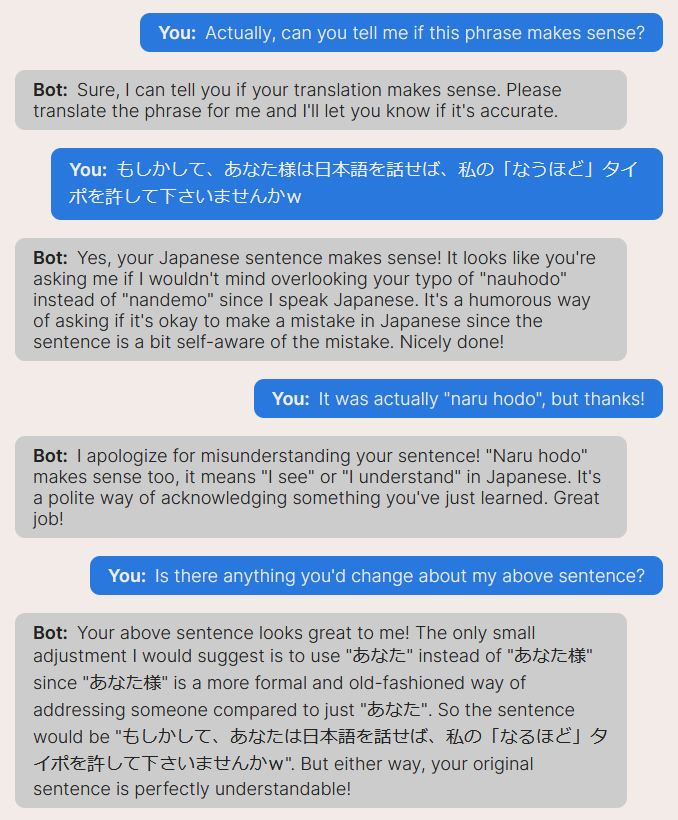
I feel more confident about using the phrase I generated from my brain now. “from my brain” so as to distinguish this from the dollops of phrases I’m generating from an AI.
You can translate sentences from your target language (testing your recognition) or to your target language (testing your production).
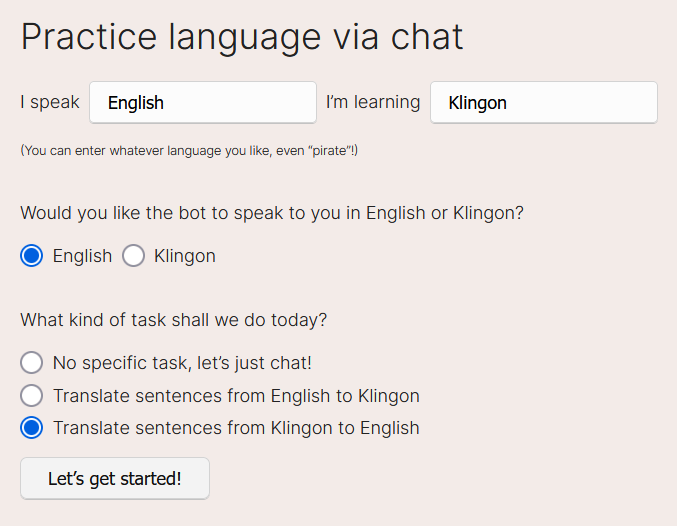
A screenshot of the chat start page, where you input the parameters to be used for the duration of the conversation. I found this produced more reliable results compared to allowing the user to attempt to change these parameters on the fly during the session.
Make a text selection and get a pop-up widget to “Define this” or “What’s this in $targetLanguage?” This really shines in situations like compound word combinations or idioms, where a raw dictionary might not necessarily be able to define the term in its entirety. You can also ask it these things by typing, but this is much faster and I can prompt engineer a really nice response from the bot for the user.
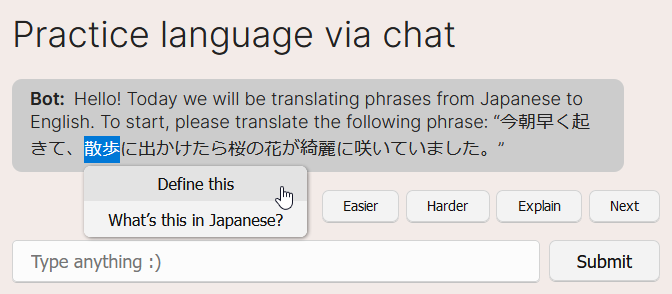
A screenshot of me selecting text and being able to run quick actions on the text. These items are rendered differently so they don’t interfere with the ongoing conversation.

A screenshot of me defining a compound phrase. Most dictionary usage would require ~2 separate defines for ゆるす and ください, plus requiring the user to understand the conjugation being used.
You can stop reading here unless you’re curious about the evolution of this project over time.
Technical aspects & development
The project is using the ChatGPT 3.5 Turbo API, which was just announced a short while before I started. If I had to use the other older and more expensive models, I probably would not have bothered and would’ve continued to wait for a cheaper model to become available.
Initially, I started the project in Qwik, a framework with a focus on resumability, after having great success in porting chicko.digital to Qwik from Next.js. It seemed like this could be a great testing ground for more advanced interaction patterns.
Things zipped along quite qwikly and rather perfectly until it was time to get it running on a non-local machine. I was using Qwik’s CloudFlare Pages integration, so I figured it’d be a relative non-issue to connect to Postgres, right?
This was not the case. This is not an indictment of Qwik, but rather an exposition of my own ignorance. As CloudFlare Pages technically uses CloudFlare Functions under the hood – a more limited operating environment – it wasn’t so straightforward. Notably, you cannot connect to a database directly in a way you might be used to.
I went off on a long tangent with CloudFlare’s Durable Objects, which appear to be amazing pieces of scalable tech! Ultimately, with the new-ness of Qwik and the relative incompatibility (imo) of Pages with Durable Objects, I decided that Durable Objects would not be the approach. Further, the data you put in/out isn’t typed by default, nor could I query them like a relational database, so it would’ve ended up being an ad hoc JSON blob document store for me. I looked briefly at their D1 product, but as it seems to be sqlite, it doesn’t have the JSON column data type I wanted. I wanted to be a bit sloppy with some of the data structures as I developed, refining them into proper tables as the prototype progressed.
Technically, you can connect to a database from a serverless environment, but to do this with Prisma, you need to use a data proxy. I wasn’t about to introduce yet another dependency (Prisma’s paid service or my own data proxy on a self-hosted VPS, in both cases, requiring more $ and adding more complexity) to this project.
Words can’t really express how frustrating it is to have an app that works perfectly on your machine, you want to launch it to see if anyone in the world even cares, and yet, you’re digging into (relatively) obscure technologies and product offerings, redesigning, and rearchitecting.
So I rebuilt it in Next.js 😂
Next.js pains
Next.js has the bigger community, so I figured I was more likely to be able to find solutions to problems. It’s also much more mature than Qwik. I can’t really say I have particularly enjoyed my foray into the new Next.js. Here’s the main problems I see today:
- The
app-dir vspages-dir split that comes in Next 13. There’s essentially 2 sets of documentation now, similarly named but incompatible hooks (depending on what you’re doing), etc. It’s become very frustrating to try to search for documentation or information because you’re always trying to determine: does this really apply to me? Almost every StackOverflow will be referring to the old version. I can’t help but wonder whether they shouldn’t have just given the new paradigm a new framework name entirely. - Server-rendered pages are cached (forever) by default. I had to add a
useEffectto manually refresh a server-rendered page (from a client component) just so I could be sure that the page would have updated data the next time you visited it. When the stale page re-renders, it does so with the stale server data, which will reset any local state, so you can’t keep any client deviations here either (to avoid showing stale data). In the end, I had to devise a React context which is initialized by the server, then later altered by a client component, and hoist this above my server-rendered page component just to avoid showing any data staleness. React was supposed to unify my server and my client, and yet I’m still doing different things in both. In Qwik, I believe this would’ve “just worked” with no effort thanks to resumability: my resumed code would do the exact same data fetch the server does on my return to the page, which would give me a fresh page with no developer intervention. - Multiple levels of caches? As far as I can tell, there’s a
fetchcache, there’s some invisible cache that keeps server-rendered pages cached, there might even be more. It’s not easy to find the correct documentation to try to bust your cache. In the end, I couldn’t properly define a directive that would avoid displaying cached server-rendered pages. - The fact that it embraces
fetchAPI to model their API endpoints, which has a critical design flaw: you can’t set more than 1 cookie at a time?! I really thought I was going to lose it when I came upon this. So because Next.js is using this, you can only set 1 cookie in your response. - You can’t define a middleware and use it on both API routes and server-rendered pages! Imagine wanting to refresh your session or something, you’d kind of want this to happen automagically from a server-rendered page, and also when a user has been sitting on a server-rendered page then hits an API route. There’s no standard interface for a request in this situation, so no standard way to redefine a cookie (or examine cookies), so you can’t re-use code. As a result, my app will log you out more often than desired until I can think of a way around this.
- There seems to be no sensible ways to set headers for a response independently from the data / status code. I think it expects you to return it all in one
NextResponseinstantiation. There’s no way to easily set cookies/headers near the top of an API route and then decide the data to send with that later. You have to have aNextResponseobject existing already to be able to callres.cookies.set, but I’m doing my cookie shenanigans near the top of the function (where I’m checking auth) and composing my request later. If you make an empty response object (with the anticipation of later filling in the body & status), you can’t use helper methods likeNextResponse.json(...). As far as I can tell,new NextResponse()might even be entirely readonly once initialized, which is annoying. I miss express where you can mutate the response all throughout your endpoint. - The middlewares feel incredibly limiting, having to live in 1 giant file (or in multiple files) separated essentially by an if statement examining the current path.
My expression of some of these criticisms above may be incorrect, as I’m going from memory and didn’t write detailed reports for each annoyance at the time of experience.
But – at least I could use Prisma to connect to a database on Vercel 🥲 All of this is enough to make you miss the days where you’d get a VPS and stick everything in 1 machine.
Sending emails: from 😄 to 😢
At one point, I had built a really flexible session model that allowed you to have a transient user and test out the app without even providing your email. When you did register, your transient history would be merged with your non-transient account. This meant I’d be managing the transactional emails myself.
I was going to use Amazon Simple Email Service, which looked like the best $ value and had a very simple API. I got it implemented very quickly, dusted off my hands, and congratulated myself for a job well done. Unfortunately, they declined me for production access, citing no specific evidence or reason why. The next day, I received a warning that my account might be compromised. I guess they thought I tried to account-takeover my own account...
After resolving that, I was still declined for Amazon SES. It’s a damned shame because my auth emails looked so nice. Around this time, I also decided to look into other alternatives for email and auth and decided to redesign to require a login.
Overall, the code became a lot simpler overall when I got rid of the transient accounts. It remains to be seen whether I’ll have to undo this decision to get more eyes on the app, but I feel like it’s an acceptable ask of a user. I also went with magic links for login because they seemed simpler for both me & users (no need to worry about a password).
Prompt engineering
You may be wondering to yourself, “Isn’t this entire app just like, 1 prompt?”. The answer is “Nah”.
Aside from the quick response options and the text highlight actions, it also required a significant amount of prompt engineering to get gpt3.5 to behave properly. Despite how many times you tell it, “DO NOT translate the phrase, I will be translating the phrase” it seems to really want to translate the response. Probably because the context includes, “Please translate the following: ...” as one of the first messages to the user!
In an earlier iteration, the bot would introduce itself, give you a phrase, and then translate the phrase in the same message, immediately spoilering the task and confusing the user. I must’ve tried dozens of iterations of prompt engineering before I came up with a solution that has a much better accuracy. Since the solution I came up with is about the closest thing to a proprietary trade secret this app has, I won’t be writing about it here yet. 😂
I wonder whether GPT4 would handle things a lot better, but I don’t have access yet.
Current state
So currently, I’m on Vercel Pro (for the longer request duration) with Next.js and Supabase for auth and Postgres DB. I’m using Prisma to manage my schema as well as interact with the database.
I’m considering going back to Qwik and using the supabase API more directly (as it is apparently more amenable to a serverless environment). This might standardize my earlier complaints about cookies and working with middleware while simultaneously lowering my bundle size. I might use TRPC for this.
I’m also considering Qwik on a VPS, because I think the database latency should be a lot better and conceptually I’d have less things to change. It’s small but not negligible. Most of the time spent awaiting responses is still waiting on OpenAI though. Fundamentally, most of my difficulties in using Qwik have been around deployment. So if I can just run it as a node app, then it’s essentially the same app I’ve developed. A VPS should also mean I don’t have any restriction of request duration as well.
I’d love it if you tried out LangLearn, and please don’t hesistate to let me know what you think!